6 Juntando dados
Existem duas grandes formas de junção de dados: UNIÃO e CRUZAMENTO.
Para que uma união seja possível, os dois conjuntos de dados precisam ter os mesmos campos. Para que um cruzamento seja possível, os dois conjuntos precisam ter pelo menos um campo em comum.
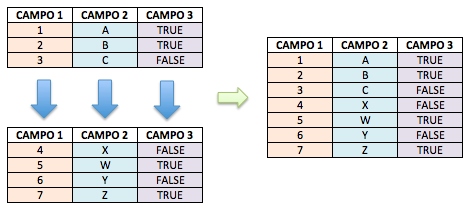
Figura 6.1: União de tabelas
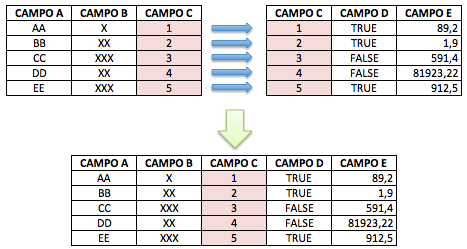
Figura 6.2: Cruzamento de tabelas
6.1 União de dados (Union)
A união de dados é mais intuitiva. Basta ter a mesma quantidade de campos e que estes estejam “alinhados”. A função mais usada para isso é o famoso rbind() (Row Bind). Caso os campos tenham exatamente os mesmos nomes e tipo, o rbind() consegue fazer a união perfeitamente.
dados2016 <- data.frame(ano = c(2016, 2016, 2016),
valor = c(938, 113, 1748),
produto = c('A', 'B', 'C'))
dados2017 <- data.frame(valor = c(8400, 837, 10983),
produto = c('H', 'Z', 'X'),
ano = c(2017, 2017, 2017))
dados.finais <- rbind(dados2016, dados2017)
dados.finais## ano valor produto
## 1 2016 938 A
## 2 2016 113 B
## 3 2016 1748 C
## 4 2017 8400 H
## 5 2017 837 Z
## 6 2017 10983 XA união de dados é a forma mais simples de juntá-los.
6.2 Cruzamento de Dados (Join)
O cruzamento de dados é um pouco mais complexo, mas nem por isso chega a ser algo difícil.
Para entender-se como fazer “joins” (cruzamentos), é preciso compreender-se o conceito de chave. Entenda chave como uma coluna que está presente da mesma forma em dois conjuntos de dados distintos. O conceito completo de chave é bem mais complexo que isto, mas, para começarmos a entender e usar os joins, basta usar essa intuição.
Tendo esse conceito simplificado de chave em mente, a primeira coisa que se deve fazer quando for preciso cruzar dois conjuntos de dados é tentar identificar quais os campos chaves, ou seja, quais campos estão presentes nos dois grupos.
O que acontece quando nem todos os códigos de um grupo estão no outro? E quando um grupo tem códigos repetidos em várias linhas? Para responder a essas e outras perguntas precisamos conhecer os diferentes tipos de joins. Existe pelo menos uma dezena de tipos de joins, mas 90% das vezes você precisará apenas dos tipos básicos que explicaremos a seguir. Usaremos o pacote dplyr para aplicar os joins. O R base possui a função merge() para joins, se tiver curiosidade procure mais sobre ela depois.
Referências: Documentação das funções *_join
6.2.1 Inner Join (ou apenas Join)
Trata-se do join mais simples, mais básico e mais usado dentre todos os outros tipos. O seu comportamento mantém no resultado apenas as linhas presentes nos dois conjuntos de dados que estão sendo cruzados. O inner join funciona da seguinte forma:
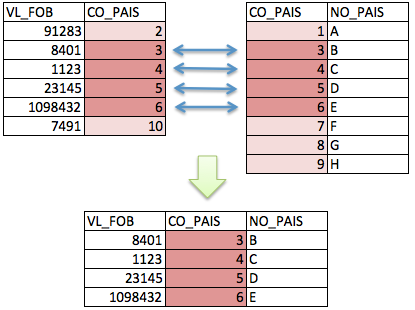
Figura 6.3: Cruzamento de tabelas
A tabela final, após o cruzamento, conterá as linhas com as chaves que estiverem em AMBOS os conjuntos de dados. As linhas com chaves que não estão em ambos serão descartadas. Esta característica torna o inner join muito útil para fazer-se filtros.
Vamos utilizar dados já disponíveis no dplyr para testar os joins:
## # A tibble: 3 x 2
## name band
## <chr> <chr>
## 1 Mick Stones
## 2 John Beatles
## 3 Paul Beatles## # A tibble: 3 x 2
## name plays
## <chr> <chr>
## 1 John guitar
## 2 Paul bass
## 3 Keith guitar## tibble [3 × 2] (S3: tbl_df/tbl/data.frame)
## $ name: chr [1:3] "Mick" "John" "Paul"
## $ band: chr [1:3] "Stones" "Beatles" "Beatles"## tibble [3 × 2] (S3: tbl_df/tbl/data.frame)
## $ name : chr [1:3] "John" "Paul" "Keith"
## $ plays: chr [1:3] "guitar" "bass" "guitar"## # A tibble: 2 x 3
## name band plays
## <chr> <chr> <chr>
## 1 John Beatles guitar
## 2 Paul Beatles bassRepare que, nesse caso, a chave é a coluna name. Repare também que os dois conjuntos têm três registros. Então, por que o resultado final só tem dois registros? A resposta é simples: porque o comportamento do join é justamente retornar apenas as linhas em que as chaves coincidiram (efeito de filtro).
Vamos fazer o mesmo experimento com band_intruments2:
## # A tibble: 3 x 2
## artist plays
## <chr> <chr>
## 1 John guitar
## 2 Paul bass
## 3 Keith guitar## tibble [3 × 2] (S3: tbl_df/tbl/data.frame)
## $ artist: chr [1:3] "John" "Paul" "Keith"
## $ plays : chr [1:3] "guitar" "bass" "guitar"## # A tibble: 2 x 3
## name band plays
## <chr> <chr> <chr>
## 1 John Beatles guitar
## 2 Paul Beatles bassRepare que, dessa vez, tivemos que especificar qual a coluna chave para que o join aconteça.
Mais um exemplo:
empregados <- read_csv('dados/Employees.csv')
departamentos <- read_csv('dados/Departments.csv')
str(empregados)## tibble [6 × 4] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ Employee : num [1:6] 1 2 3 4 5 6
## $ EmployeeName: chr [1:6] "Alice" "Bob" "Carla" "Daniel" ...
## $ Department : num [1:6] 11 11 12 12 13 21
## $ Salary : num [1:6] 800 600 900 1000 800 700
## - attr(*, "spec")=
## .. cols(
## .. Employee = col_double(),
## .. EmployeeName = col_character(),
## .. Department = col_double(),
## .. Salary = col_double()
## .. )## tibble [4 × 3] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ Department : num [1:4] 11 12 13 14
## $ DepartmentName: chr [1:4] "Production" "Sales" "Marketing" "Research"
## $ Manager : num [1:4] 1 4 5 NA
## - attr(*, "spec")=
## .. cols(
## .. Department = col_double(),
## .. DepartmentName = col_character(),
## .. Manager = col_double()
## .. )## # A tibble: 6 x 4
## Employee EmployeeName Department Salary
## <dbl> <chr> <dbl> <dbl>
## 1 1 Alice 11 800
## 2 2 Bob 11 600
## 3 3 Carla 12 900
## 4 4 Daniel 12 1000
## 5 5 Evelyn 13 800
## 6 6 Ferdinand 21 700## # A tibble: 4 x 3
## Department DepartmentName Manager
## <dbl> <chr> <dbl>
## 1 11 Production 1
## 2 12 Sales 4
## 3 13 Marketing 5
## 4 14 Research NA## # A tibble: 3 x 6
## Employee EmployeeName Department.x Salary Department.y DepartmentName
## <dbl> <chr> <dbl> <dbl> <dbl> <chr>
## 1 1 Alice 11 800 11 Production
## 2 4 Daniel 12 1000 12 Sales
## 3 5 Evelyn 13 800 13 MarketingNovamente tivemos o mesmo efeito, listamos apenas os empregados que são gerentes de departamento.
Acontece que existem situações em que esse descarte de registro do inner join não é interessante. Nesses casos usamos outros tipos de join: os Outer Joins. Existem três tipos básicos de outer join: left outer join (ou só left join), right outer join (ou só right join) e full outer join (ou apenas full join).
6.2.2 Left Outer Join
Chama-se LEFT outer join pois todos os registros do “conjunto à esquerda” estarão presentes no resultado final, além dos registros à direita que coincidirem na chave. Podemos usar no caso a seguir:
## # A tibble: 3 x 3
## name band plays
## <chr> <chr> <chr>
## 1 Mick Stones <NA>
## 2 John Beatles guitar
## 3 Paul Beatles bass## # A tibble: 3 x 2
## artist plays
## <chr> <chr>
## 1 John guitar
## 2 Paul bass
## 3 Keith guitarReparem no efeito: mesmo Mick não tendo referência no conjunto de dados “à direita” (band_instruments2), ele apareceu no registro final com NA, no campo que diz respeito ao conjunto à direita. Da mesma forma, Keith não está presente no conjunto final, pois não tem referência no conjunto à esquerda.
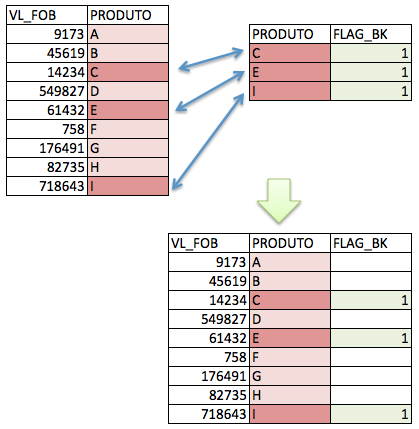
Figura 6.4: Cruzamento de tabelas
Repare que a “posição” das tabelas faz diferença. No caso da nossa manipulação de exmeplo, aplicamos o left join pois a tabela que queríamos preservar estava “à esquerda” na manipulação.
## # A tibble: 6 x 6
## Employee EmployeeName Department.x Salary Department.y DepartmentName
## <dbl> <chr> <dbl> <dbl> <dbl> <chr>
## 1 1 Alice 11 800 11 Production
## 2 2 Bob 11 600 NA <NA>
## 3 3 Carla 12 900 NA <NA>
## 4 4 Daniel 12 1000 12 Sales
## 5 5 Evelyn 13 800 13 Marketing
## 6 6 Ferdinand 21 700 NA <NA>6.2.3 Right Outer Join
O princípio é EXATAMENTE o mesmo do left join. A única diferença é a permanência dos registros do conjunto à direita. Podemos chegar ao mesmo resultado anterior apenas mudando os data frames de posição na manipulação.
## # A tibble: 6 x 6
## Department.x DepartmentName Manager EmployeeName Department.y Salary
## <dbl> <chr> <dbl> <chr> <dbl> <dbl>
## 1 11 Production 1 Alice 11 800
## 2 12 Sales 4 Daniel 12 1000
## 3 13 Marketing 5 Evelyn 13 800
## 4 NA <NA> 2 Bob 11 600
## 5 NA <NA> 3 Carla 12 900
## 6 NA <NA> 6 Ferdinand 21 700## # A tibble: 6 x 6
## Employee EmployeeName Department.x Salary Department.y DepartmentName
## <dbl> <chr> <dbl> <dbl> <dbl> <chr>
## 1 1 Alice 11 800 11 Production
## 2 2 Bob 11 600 NA <NA>
## 3 3 Carla 12 900 NA <NA>
## 4 4 Daniel 12 1000 12 Sales
## 5 5 Evelyn 13 800 13 Marketing
## 6 6 Ferdinand 21 700 NA <NA>A escolha entre right join e left join depende completamente da ordem em que você escolher realizar as operações. Via de regra, um pode ser substituído pelo outro, desde que a posição dos data frames se ajuste na sequência das manipulações.
6.2.4 Full Outer Join
Existem, ainda, as situações em que é necessário preservar todos os registros de ambos os conjuntos de dados. O full join tem essa característica. Nenhum dos conjuntos de dados perderá registros no resultado final, isto é, quando as chaves forem iguais, todos os campos estarão preenchidos. Quando não houver ocorrência das chaves em ambos os lados, será informado NA em qualquer um deles.
## # A tibble: 4 x 3
## name band plays
## <chr> <chr> <chr>
## 1 Mick Stones <NA>
## 2 John Beatles guitar
## 3 Paul Beatles bass
## 4 Keith <NA> guitarReparem que, dessa vez, não perdemos nenhum registro, de nenhum conjunto de dados, apenas teremos NA quando a ocorrência da chave não acontecer em alguns dos conjuntos.
O full join funciona da seguinte forma:
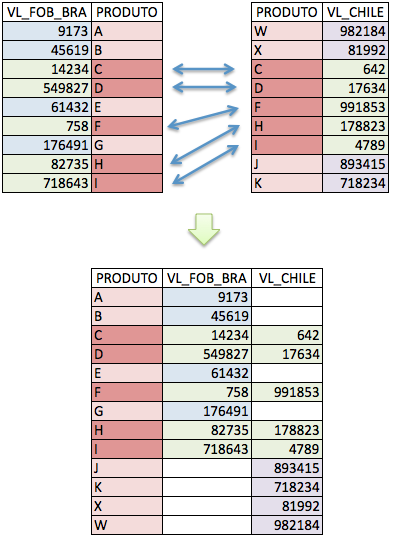
Figura 6.5: Cruzamento de tabelas
## # A tibble: 7 x 6
## Department.x DepartmentName Manager EmployeeName Department.y Salary
## <dbl> <chr> <dbl> <chr> <dbl> <dbl>
## 1 11 Production 1 Alice 11 800
## 2 12 Sales 4 Daniel 12 1000
## 3 13 Marketing 5 Evelyn 13 800
## 4 14 Research NA <NA> NA NA
## 5 NA <NA> 2 Bob 11 600
## 6 NA <NA> 3 Carla 12 900
## 7 NA <NA> 6 Ferdinand 21 700Do resultado desse full join, por exemplo, podemos concluir que não tem nenhum Manager no departamento Resarch, da mesma forma, os empregados Bob, Carla e Ferdinand não são managers de departamento nenhum.
6.3 Exercícios
- Utilizando as bases de dados do pacote
nycflights13, encontre a tabela abaixo que mostra quais aeroportos (origem e destino) tiveram mais voos. Será necessário utilizar o dataframeflightseairports.Dica: primeiro descubra as chaves.
## `summarise()` regrouping output by 'Origem' (override with `.groups` argument)## # A tibble: 217 x 3
## # Groups: Origem [3]
## Origem Destino qtd
## <chr> <chr> <int>
## 1 John F Kennedy Intl Los Angeles Intl 11262
## 2 La Guardia Hartsfield Jackson Atlanta Intl 10263
## 3 La Guardia Chicago Ohare Intl 8857
## 4 John F Kennedy Intl San Francisco Intl 8204
## 5 La Guardia Charlotte Douglas Intl 6168
## 6 Newark Liberty Intl Chicago Ohare Intl 6100
## 7 John F Kennedy Intl General Edward Lawrence Logan Intl 5898
## 8 La Guardia Miami Intl 5781
## 9 John F Kennedy Intl Orlando Intl 5464
## 10 Newark Liberty Intl General Edward Lawrence Logan Intl 5327
## # … with 207 more rows- Utilizando os dataframes abaixo, chegue no resultado a seguir:
participantes <- data.frame(
Nome = c('Carlos', 'Maurício', 'Ana Maria', 'Rebeca', 'Patrícia'),
Estado = c('Brasília', 'Minas Gerais', 'Goiás', 'São Paulo', 'Ceará'),
Idade = c(23, 24, 22, 29, 28)
)
aprovados <- data.frame(
Nome = c('Carlos', 'Patrícia'),
Pontuacao = c(61, 62)
)
eliminados <- data.frame(
Nome = c('Maurício', 'Ana Maria', 'Rebeca'),
Pontuacao = c(49, 48, 48)
)
participantes## Nome Estado Idade
## 1 Carlos Brasília 23
## 2 Maurício Minas Gerais 24
## 3 Ana Maria Goiás 22
## 4 Rebeca São Paulo 29
## 5 Patrícia Ceará 28## Nome Pontuacao
## 1 Carlos 61
## 2 Patrícia 62## Nome Pontuacao
## 1 Maurício 49
## 2 Ana Maria 48
## 3 Rebeca 48## Nome Estado Idade Pontuacao Resultado
## 1 Carlos Brasília 23 61 Aprovado
## 2 Maurício Minas Gerais 24 49 Eliminado
## 3 Ana Maria Goiás 22 48 Eliminado
## 4 Rebeca São Paulo 29 48 Eliminado
## 5 Patrícia Ceará 28 62 Aprovado6.4 Exercícios gerais do Tidyverse
Para fazer as questões abaixo será necessário usar funções também dos capítulos anteriores.
Carregue os pacotes
tidyverseejanitor.Baixe o dataset de Super Heróis do Kaggle. Descompacte o arquivo e importe os dois arquivos para o R: salve o arquivo
super_hero_powers.csvno objetohero_powerse o arquivoheroes_information.csvno objetohero_info. Use também na funçãoread_csvo argumentona = c("", "-", "NA"))para que linhas com traço ou vazias sejam convertidas para NA. Observe as colunas presentes nos datasets usando a funçãoglimpse.Use a função
janitor::clean_names()para limpar os nomes das colunas.No caso de
hero_info, remova a primeira coluna.Em
hero_powers, converta todas as colunas com exceção da primeira para o tipological.Em
hero_info, na colunapublisher, observe quantas editoras diferentes existem no dataset. Substitua Marvel Comics por Marvel, DC Comics por DC e todas as outras editoras pelo termo “Outros”. Dica: uma das possíveis maneiras de fazer isso é usando uma combinação das funçõesdplyr::mutate()edplyr::case_when().Em
hero_info, quais raças (colunarace) são exclusivas de cada editora?Em
hero_info, quais cores de olhos (colunaeye_color) são mais comuns para cada sexo (colunagender)? Filtre o top 3 para cadda sexo.Em
hero_powers, calcule o percentual de heróis que possui cada habilidade descrita nas colunas (Dica: é possível calcular a soma ou percentual de um vetor lógico, poisTRUEequivale a 1 eFALSEa 0). Use a funçãodplyr::summarise_ifpara aplicar a função em todas as colunas cuja classe élogical.Repita o item anterior, usando uma abordagem mais tidy: converta o formato do dataframe
hero_powerspara o formato long. Ele passará a possuir apenas 3 colunas:hero_names,poderepossui_poderusando a funçãotidyr::gather(). Então, calcule a média da colunapossui_poderagrupado pela colunapoder.Junte os dois dataframes em um só, chamado
hero. A função a ser usada éinner_join(). Pense bem em qual será a ordem dos dataframes nos argumentos da função e qual será a chave usada no argumentobypara unir as duas tabelas.No dataframe
hero, calcule o percentual de herois de cada editora que são telepatas.No dataframe
hero, selecione as colunasname,publisher,flighteweight, filtre os heróis que podem voar e retorne os 10 de maior peso.Salve o dataframe chamado
herono arquivoherois_completo.csvusando a funçãoreadr::write_csv().