5 Limpando dados
No dia a dia de quem trabalha com dados, infelizmente, é muito comum se deparar com dados formatados de um jeito bastante complicado de se manipular. Isso acontece pois a forma de se trabalhar com dados é muito diferente da forma de se apresentar ou visualizar dados. Resumindo: “olhar” dados requer uma estrutura bem diferente de “mexer” com dados. Limpeza de dados também é considerada parte da manipulação de dados.
5.1 O formato “ideal” dos dados
É importante entender um pouco mais sobre como os dados podem ser estruturados antes de entrarmos nas funções de limpeza. O formato ideal para analisar dados, visualmente, é diferente do formato ideal para analisá-los de forma sistemática. Observe as duas tabelas a seguir:
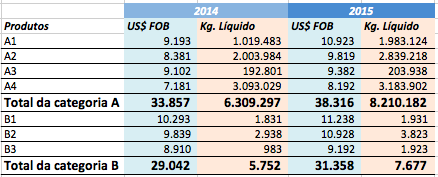
Figura 5.1: Tabela wide
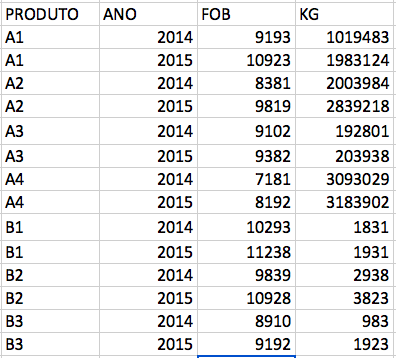
Figura 5.2: Tabela long
A primeira tabela é mais intuitiva para análise visual, pois faz uso de cores e propõe uma leitura natural, da esquerda para a direita. Utiliza, ainda, elementos e estruturas que guiam seus olhos por uma análise de forma simples. Já a segunda tabela é um pouco árida para se interpretar “no olho”.
Há uma espécie de regra geral a qual diz que um dado bem estruturado deve conter uma única variável em uma coluna e uma única observação em uma linha.
Observando-se a primeira tabela, com essa regra em mente, podemos perceber que as observações de ano estão organizadas em colunas. Apesar de estar num formato ideal para análise visual, esse formato dificulta bastante certas análises sistemáticas. O melhor a se fazer é converter a primeira tabela a um modelo mais próximo o possível da segunda tabela.
Infelizmente, não temos como apresentar um passo a passo padrão para limpeza de dados, pois isso depende completamente do tipo de dado que você receber, da análise que você quer fazer e da sua criatividade em manipulação de dados. Mas conhecer os pacotes certos ajuda muito nessa tarefa.
Lembre-se: é muito mais fácil trabalhar no R com dados “bem estruturados”, onde cada coluna deve ser uma única variável e cada linha deve ser uma única observação.
Na contramão da limpeza de dados, você provavelmente terá o problema contrário ao final da sua análise. Supondo que você organizou seus dados perfeitamente, conseguiu executar os modelos que gostaria, gerou diversos gráficos interessantes e está satisfeito com o resultado, você ainda precisará entregar relatórios finais da sua análise em forma de tabelas sumarizadas e explicativas, de modo que os interessados possam entender facilmente, apenas com uma rápida análise visual. Neste caso, que tipo de tabela seria melhor produzir? Provavelmente, quem for ler seus relatórios entenderá mais rapidamente as tabelas mais próximas do primeiro exemplo mostrado.
É importante aprender a estruturar e desestruturar tabelas de todas as formas possíveis.
Para exemplificar, veja algumas tabelas disponíveis no pacote tidyverse, ilustrando os diferentes tipos de organização nos formatos wide e long. Todas as tabelas possuem os mesmos dados e informações:
## # A tibble: 6 x 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583## # A tibble: 12 x 4
## country year type count
## <chr> <int> <chr> <int>
## 1 Afghanistan 1999 cases 745
## 2 Afghanistan 1999 population 19987071
## 3 Afghanistan 2000 cases 2666
## 4 Afghanistan 2000 population 20595360
## 5 Brazil 1999 cases 37737
## 6 Brazil 1999 population 172006362
## 7 Brazil 2000 cases 80488
## 8 Brazil 2000 population 174504898
## 9 China 1999 cases 212258
## 10 China 1999 population 1272915272
## 11 China 2000 cases 213766
## 12 China 2000 population 1280428583## # A tibble: 6 x 3
## country year rate
## * <chr> <int> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/1280428583## # A tibble: 3 x 3
## country `1999` `2000`
## * <chr> <int> <int>
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766## # A tibble: 3 x 3
## country `1999` `2000`
## * <chr> <int> <int>
## 1 Afghanistan 19987071 20595360
## 2 Brazil 172006362 174504898
## 3 China 1272915272 1280428583## # A tibble: 6 x 4
## country century year rate
## * <chr> <chr> <chr> <chr>
## 1 Afghanistan 19 99 745/19987071
## 2 Afghanistan 20 00 2666/20595360
## 3 Brazil 19 99 37737/172006362
## 4 Brazil 20 00 80488/174504898
## 5 China 19 99 212258/1272915272
## 6 China 20 00 213766/12804285835.2 Pacote tidyr
Apesar de existirem diversas possibilidades de situações que necessitem de limpeza de dados, a conjugação de três pacotes consegue resolver a grande maioria dos casos: dplyr, tidyr, stringr.
O pacote tidyr é mais um dos pacotes criados por Hadley Wickham. Este fato, por si só, já traz algumas vantagens: ele se integra perfeitamente com o dplyr, usando o conector %>%, e tem a sintaxe de suas funções bastante intuitiva.
O tidyr também tem suas funções organizadas em pequenos verbetes, onde cada um representa uma tarefa para organizar os dados. Os verbetes básicos que abordaremos são os seguintes:
pivot_longer()
pivot_wider()
separate()spread()unite()
separate_rows()
Figura 5.3: Tabela long
Referências: Site do pacote tidyr
5.2.1 pivot_longer()
A função pivot_longer(), antiga gather(), serve para agrupar duas ou mais colunas e seus respectivos valores (conteúdos) em pares. Assim, o resultado após o agrupamento é sempre duas colunas. A primeira delas possui observações cujos valores chave eram as colunas antigas e a segunda possui os valores respectivos relacionados com as colunas antigas. Na prática, a função gather diminui o número de colunas e aumenta o número de linhas de nossa base de dados.
Usaremos dados disponíveis no R base para exemplificar:
## # A tibble: 18 x 11
## religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k`
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Agnostic 27 34 60 81 76 137
## 2 Atheist 12 27 37 52 35 70
## 3 Buddhist 27 21 30 34 33 58
## 4 Catholic 418 617 732 670 638 1116
## 5 Don’t k… 15 14 15 11 10 35
## 6 Evangel… 575 869 1064 982 881 1486
## 7 Hindu 1 9 7 9 11 34
## 8 Histori… 228 244 236 238 197 223
## 9 Jehovah… 20 27 24 24 21 30
## 10 Jewish 19 19 25 25 30 95
## 11 Mainlin… 289 495 619 655 651 1107
## 12 Mormon 29 40 48 51 56 112
## 13 Muslim 6 7 9 10 9 23
## 14 Orthodox 13 17 23 32 32 47
## 15 Other C… 9 7 11 13 13 14
## 16 Other F… 20 33 40 46 49 63
## 17 Other W… 5 2 3 4 2 7
## 18 Unaffil… 217 299 374 365 341 528
## # … with 4 more variables: `$75-100k` <dbl>, `$100-150k` <dbl>,
## # `>150k` <dbl>, `Don't know/refused` <dbl>Para transformar a tabela acima do formato wide para o long, usamos a função:
relig_income %>%
pivot_longer(
# o argumento cols controla quais colunas serão (ou não serão) transformadas
cols = -religion,
#names_to controla o nome da nova coluna que irá receber os nomes das colunas transpostas
names_to = "renda",
# values_to controla o nome da nova coluna que irá recebebr os valores das colunas transpostas
values_to = "quantidade")## # A tibble: 180 x 3
## religion renda quantidade
## <chr> <chr> <dbl>
## 1 Agnostic <$10k 27
## 2 Agnostic $10-20k 34
## 3 Agnostic $20-30k 60
## 4 Agnostic $30-40k 81
## 5 Agnostic $40-50k 76
## 6 Agnostic $50-75k 137
## 7 Agnostic $75-100k 122
## 8 Agnostic $100-150k 109
## 9 Agnostic >150k 84
## 10 Agnostic Don't know/refused 96
## # … with 170 more rows
Referências: Documentação da função pivot_longer()
5.2.2 pivot_wider()
É a operação antagônica do pivot_longer(). Ela espalha os valores de duas colunas em diversos campos para cada registro: os valores de uma coluna viram o nome das novas colunas, e os valores de outra viram valores de cada registro nas novas colunas. O output tem mais colunas e menos linhas.
## # A tibble: 104 x 5
## GEOID NAME variable estimate moe
## <chr> <chr> <chr> <dbl> <dbl>
## 1 01 Alabama income 24476 136
## 2 01 Alabama rent 747 3
## 3 02 Alaska income 32940 508
## 4 02 Alaska rent 1200 13
## 5 04 Arizona income 27517 148
## 6 04 Arizona rent 972 4
## 7 05 Arkansas income 23789 165
## 8 05 Arkansas rent 709 5
## 9 06 California income 29454 109
## 10 06 California rent 1358 3
## # … with 94 more rowsus_rent_income %>%
pivot_wider(
#names_from controla de qual coluna serão criados os nomes das novas colunas
names_from = variable,
# values_from controla as colunas cujos valores serão os valores das novas colunas
values_from = c(estimate, moe)
)## # A tibble: 52 x 6
## GEOID NAME estimate_income estimate_rent moe_income moe_rent
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 01 Alabama 24476 747 136 3
## 2 02 Alaska 32940 1200 508 13
## 3 04 Arizona 27517 972 148 4
## 4 05 Arkansas 23789 709 165 5
## 5 06 California 29454 1358 109 3
## 6 08 Colorado 32401 1125 109 5
## 7 09 Connecticut 35326 1123 195 5
## 8 10 Delaware 31560 1076 247 10
## 9 11 District of… 43198 1424 681 17
## 10 12 Florida 25952 1077 70 3
## # … with 42 more rows
Referências: Documentação da função pivot_wider()
5.2.3 separate
O separate() é usado para separar duas variáveis que estão em uma mesma coluna. Lembre-se: cada coluna deve ser apenas uma única variável! É muito normal virem variáveis juntas em uma única coluna, mas nem sempre isso é prejudicial, cabe avaliar quando vale a pena separá-las.
Usaremos o exemplo da table3 para investigar:
table3.wide <- table3 %>%
separate(rate, into = c("cases", "population"), sep='/')
head(table3.wide)## # A tibble: 6 x 4
## country year cases population
## <chr> <int> <chr> <chr>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583
Referências: Documentação da função separate
5.2.4 unite
A operação unite() é o oposto da separate(), ela pega duas colunas (variáveis) e transforma em uma só. É muito utilizada para montar relatórios finais ou tabelas para análise visual. Aproveitemos o exemplo em table2 para montarmos uma tabela final comparando a “case” e “population” de cada país, em cada ano.
table2.relatorio <- table2 %>%
unite(type_year, type, year) %>%
spread(key = type_year, value = count, sep = '_')
table2.relatorio## # A tibble: 3 x 5
## country type_year_cases… type_year_cases… type_year_popul…
## <chr> <int> <int> <int>
## 1 Afghan… 745 2666 19987071
## 2 Brazil 37737 80488 172006362
## 3 China 212258 213766 1272915272
## # … with 1 more variable: type_year_population_2000 <int>
Referências: Documentação da função unite
O primeiro parâmetro é a coluna que desejamos criar, os próximos são as colunas que desejamos unir e, por fim, temos o sep, que representa algum símbolo opcional para ficar entre os dois valores na nova coluna.
5.2.5 separate_rows
Do mesmo modo que separate() quebra uma coluna em várias, separate_rows() quebra uma linha em várias de acordo com um separador. Essa função é muito útil para lidar com dados sujos. Observe o exemplo:
# criar dataframe de exemplo
exemplo <- tibble(grupo = c("a", "a", "b","b"),
y = c("1, 2", "3;4", "1,2,3", "4"))
exemplo %>%
separate_rows(y, sep = ",")## # A tibble: 7 x 2
## grupo y
## <chr> <chr>
## 1 a "1"
## 2 a " 2"
## 3 a "3;4"
## 4 b "1"
## 5 b "2"
## 6 b "3"
## 7 b "4"
Referências: Documentação da função separate_rows
5.3 Exercicios
Transforme a table1 para a table2 usando pivot_longer()
Transforme a table2 para a table1 usando pivot_wider()
Transforme a table5 para a table1 e para a table2